Интегрально локальная теорема муавра лапласа. Теоремы муавра-лапласа
Рассмотрим последовательность из $n$ независимых опытов, в каждом из которых событие $A$ может произойти с вероятностью $p$, либо не произойти — с вероятностью $q=1-p$. Обозначим через P n (k ) вероятность того, что событие $A$ произойдет ровно $k$ раз из $n$ возможных.
В таком случае величину P n (k ) можно найти по теореме Бернулли (см. урок «Схема Бернулли. Примеры решения задач »):
Эта теорема прекрасно работает, однако у нее есть недостаток. Если $n$ будет достаточно большим, то найти значение P n (k ) становится нереально из-за огромного объема вычислений. В этом случае работает Локальная теорема Муавра — Лапласа , которая позволяют найти приближенное значение вероятности:
Локальная теорема Муавра — Лапласа. Если в схеме Бернулли число $n$ велико, а число $p$ отлично от 0 и 1, тогда:
Функция φ (x ) называется функцией Гаусса. Ее значения давно вычислены и занесены в таблицу, которой можно пользоваться даже на контрольных работах и экзаменах.
Функция Гаусса обладает двумя свойствами, которые следует учитывать при работе с таблицей значений:
- φ (−x ) = φ (x ) — функция Гаусса — четная;
- При больших значениях x имеем: φ (x ) ≈ 0.
Локальная теорема Муавра — Лапласа дает отличное приближение формулы Бернулли, если число испытаний n достаточно велико. Разумеется, формулировка «число испытаний достаточно велико» весьма условна, и в разных источниках называются разные цифры. Например:
- Часто встречается требование: n · p · q > 10. Пожалуй, это минимальная граница;
- Другие предлагают работать по этой формуле только для $n > 100$ и n · p · q > 20.
На мой взгляд, достаточно просто взглянуть на условие задачи. Если видно, что стандартная теорема Бернулли не работает из-за большого объема вычислений (например, никто не будет считать число 58! или 45!), смело применяйте Локальную теорему Муавра — Лапласа.
К тому же, чем ближе значения вероятностей $q$ и $p$ к 0,5, тем точнее формула. И, наоборот, при пограничных значениях (когда $p$ близко к 0 или 1) Локальная теорема Муавра — Лапласа дает большую погрешность, значительно отличаясь от настоящей теоремы Бернулли.
Однако будьте внимательны! Многие репетиторы по высшей математике сами ошибаются в подобных расчетах. Дело в том, что в функцию Гаусса подставляется довольно сложное число, содержащее арифметический квадратный корень и дробь. Это число обязательно надо найти еще до подстановки в функцию. Рассмотрим все на конкретных задачах:
Задача. Вероятность рождения мальчика равна 0,512. Найдите вероятность того, что среди 100 новорожденных будет ровно 51 мальчик.
Итак, всего испытаний по схеме Бернулли n = 100. Кроме того, p = 0,512, q = 1 − p = 0,488.
Поскольку n = 100 — это достаточно большое число, будем работать по Локальной теореме Муавра — Лапласа. Заметим, что n · p · q = 100 · 0,512 · 0,488 ≈ 25 > 20. Имеем:
Поскольку мы округляли значение n · p · q до целого числа, ответ тоже можно округлить: 0,07972 ≈ 0,08. Учитывать остальные цифры просто нет смысла.
Задача. Телефонная станция обслуживает 200 абонентов. Для каждого абонента вероятность того, что в течение одного часа он позвонит на станцию, равна 0,02. Найти вероятность того, что в течение часа позвонят ровно 5 абонентов.
По схеме Бернулли, n = 200, p = 0,02, q = 1 − p = 0,98. Заметим, что n = 200 — это неслабое число, поэтому используем Локальную теорему Муавра — Лапласа. Для начала найдем n · p · q = 200 · 0,02 · 0,98 ≈ 4. Конечно, 4 — это слишком мало, поэтому результаты будут неточными. Тем не менее, имеем:
Округлим ответ до второго знака после запятой: 0,17605 ≈ 0,18. Учитывать больше знаков все равно не имеет смысла, поскольку мы округляли n · p · q = 3,92 ≈ 4 (до точного квадрата).
Задача. Магазин получил 1000 бутылок водки. Вероятность того, что при перевозке бутылка разобьется, равна 0,003. Найти вероятность того, что магазин получит ровно две разбитых бутылки.
По схеме Бернулли имеем: n = 1000, p = 0,003, q = 0,997. Отсюда n · p · q = 2,991 ≈ 1,73 2 (подобрали ближайший точный квадрат). Поскольку число n = 1000 достаточно велико, подставляем все числа в формулу Локальной теоремы Муавра — Лапласа:
Мы сознательно оставляем лишь один знак после запятой (на самом деле там получится 0,1949...), поскольку изначально использовали довольно грубые оценки. В частности: 2,991 ≈ 1,73 2 . Тройка в числителе внутри функции Гаусса возникла из выражения n · p = 1000 · 0,003 = 3.
Локальная теорема Муавра-Лапласа { 1730 г. Муавр и Лаплас }
Если вероятность $p$ появлений события $A$ постоянна и $p\ne 0$ и $p\ne 1$, то вероятность $P_n (k)$ - того, что событие $A$ появится $k$ раз в $n$ испытаниях, равна приближенно { чем больше $n$, тем точнее } значению функции $y=\frac { 1 } { \sqrt { n\cdot p\cdot q } } \cdot \frac { 1 } { \sqrt { 2\pi } } \cdot e^ { - { x^2 } / 2 } =\frac { 1 } { \sqrt { n\cdot p\cdot q } } \cdot \varphi (x)$
при $x=\frac { k-n\cdot p } { \sqrt { n\cdot p\cdot q } } $. Имеются таблицы, где помещены значения функции $\varphi (x)=\frac { 1 } { \sqrt { 2\cdot \pi } } \cdot e^ { - { x^2 } / 2 } $
итак \begin{equation} \label { eq2 } P_n (k)\approx \frac { 1 } { \sqrt { n\cdot p\cdot q } } \cdot \varphi (x)\,\,где\,x=\frac { k-n\cdot p } { \sqrt { n\cdot p\cdot q } } \qquad (2) \end{equation}
функция $\varphi (x)=\varphi ({ -x })$ -четная.
Пример. Найти вероятность того, что событие $A$наступит ровно 80 раз при 400 испытаниях, если вероятность появления этого события в каждом испытании $p=0,2$.
Решение. Если $p=0,2$ тогда $q=1-p=1-0,2=0,8$.
$P_ { 400 } ({ 80 })\approx \frac { 1 } { \sqrt { n\cdot p\cdot q } } \varphi (x)\,\,где\,x=\frac { k-n\cdot p } { \sqrt { n\cdot p\cdot q } } $
$ \begin{array} { l } x=\frac { k-n\cdot p } { \sqrt { n\cdot p\cdot q } } =\frac { 80-400\cdot 0,2 } { \sqrt { 400\cdot 0,2\cdot 0,8 } } =\frac { 80-80 } { \sqrt { 400\cdot 0,16 } } =0 \\ \varphi (0)=0,3989\,\,P_ { 400 } ({ 80 })\approx \frac { 0,3989 } { 20\cdot 0,4 } =\frac { 0,3989 } { 8 } =0,0498 \\ \end{array} $
Интегральная теорема Муавра-Лапласа
Вероятность P наступления события $A$ в каждом испытании постоянна и $p\ne 0$ и $p\ne 1$, тогда вероятность $P_n ({ k_1 ,k_2 })$ того, что событие $A$ наступит от $k_ { 1 } $ до $k_ { 2 } $ раз в $n$ испытаниях, равна $ P_n ({ k_1 ,k_2 })\approx \frac { 1 } { \sqrt { 2\cdot \pi } } \int\limits_ { x_1 } ^ { x_2 } { e^ { - { z^2 } / 2 } dz } =\Phi ({ x_2 })-\Phi ({ x_1 })$
где $x_1 =\frac { k_1 -n\cdot p } { \sqrt { n\cdot p\cdot q } } , x_2 =\frac { k_2 -n\cdot p } { \sqrt { n\cdot p\cdot q } } $ ,где
$\Phi (x)=\frac { 1 } { \sqrt { 2\cdot \pi } } \int { e^ { - { z^2 } / 2 } dz } $ -находят по таблицам
$\Phi ({ -x })=-\Phi (x)$-нечетная
Нечетная функция. Значения в таблице даны для $x=5$, для $x>5,\Phi (x)=0,5$
Пример. Известно, что при контроле бракуется 10% изделий. На контроль отобрано 625 изделий. Какова вероятность того, что среди отобранных не менее 550 и не более 575 стандартных изделий?
Решение. Если брака 10%, то стандартных изделий 90%. Тогда по условию, $n=625, p=0,9, q=0,1, k_1 =550, k_2 =575$. $n\cdot p=625\cdot 0,9=562,5$. Получим $ \begin{array} { l } P_ { 625 } (550,575)\approx \Phi ({ \frac { 575-562,5 } { \sqrt { 625\cdot 0,9\cdot 0,1 } } })- \Phi ({ \frac { 550-562,5 } { \sqrt { 626\cdot 0,9\cdot 0,1 } } })\approx \Phi (1,67)- \Phi (-1,67)=2 \Phi (1,67)=0,9052 \\ \end{array} $
Теорема 2 (Муавра-Лапласа (локальная)). А в каждом из n независимых испытаниях равна р n испытаниях событие А наступит раз, приближенно равна (чем больше n , тем точнее) значению функции
![]() ,
,
где ![]() , . Таблица значений функции приведена в прил. 1.
, . Таблица значений функции приведена в прил. 1.
Пример 6.5. Вероятность найти белый гриб среди прочих равна . Какова вероятность того, что среди 300 грибов белых будет 75?
Решение.
По условию задачи ![]() , . Находим
, . Находим  . По таблице находим
. По таблице находим ![]() .
.
 .
.
Ответ:
![]() .
.
Теорема 3 (Муавра-Лапласа (интегральная)). Если вероятность наступления события А в каждом из n независимых испытаний равна р и отлична от нуля и единицы, а число испытаний достаточно велико, то вероятность того, что в n испытаниях число успехов m находится между и , приближенно равна (чем больше n , тем точнее)
 ,
,
где р
- вероятность появления успеха в каждом испытании, ,  , значения приведены в прил. 2.
, значения приведены в прил. 2.
Пример 6.6. В партии из 768 арбузов каждый арбуз оказывается неспелым с вероятностью . Найти вероятность того, что количество спелых арбузов будет в пределах от 564 до 600.
Решение. По условию По интегральной теореме Лапласа

Ответ:
Пример 6.7. Город ежедневно посещает 1000 туристов, которые днем идут обедать. Каждый из них выбирает для обеда один из двух городских ресторанов с равными вероятностями и независимо друг от друга. Владелец одного из ресторанов желает, чтобы с вероятностью приблизительно 0,99 все пришедшие в его ресторан туристы могли там одновременно пообедать. Сколько мест должно быть для этого в его ресторане?
Решение.
Пусть А
= «турист пообедал у заинтересованного владельца». Наступление события А
будем считать «успехом», ![]() , . Нас интересует такое наименьшее число k
, что вероятность наступления не менее чем k
«успехов» в последовательности из независимых испытаний с вероятностью успеха р
= 0,5 приблизительно равна 1 – 0,99 = 0,01. Это как раз вероятность переполнения ресторана. Таким образом, нас интересует такое наименьшее число k
, что . Применим интегральную теорему Муавра-Лапласа
, . Нас интересует такое наименьшее число k
, что вероятность наступления не менее чем k
«успехов» в последовательности из независимых испытаний с вероятностью успеха р
= 0,5 приблизительно равна 1 – 0,99 = 0,01. Это как раз вероятность переполнения ресторана. Таким образом, нас интересует такое наименьшее число k
, что . Применим интегральную теорему Муавра-Лапласа

Откуда следует, что
 .
.
Используя таблицу для Ф
(х
) (прил. 2), находим ![]() , значит . Следовательно, в ресторане должно быть 537 мест.
, значит . Следовательно, в ресторане должно быть 537 мест.
Ответ: 537 мест.
Из интегральной теоремы Лапласа можно получить формулу
 .
.
Пример 6.8. Вероятность появления события в каждом из 625 независимых испытаний равна 0,8. Найти вероятность того, что относительная частота появления события отклонится от его вероятности по абсолютной величине не более чем на 0,04.
Локальная и интегральная теоремы Лапласа
Данная статья является естественным продолжением урока о независимых испытаниях , на котором мы познакомились с формулой Бернулли и отработали типовые примеры по теме. Локальная и интегральная теоремы Лапласа (Муавра-Лапласа) решают аналогичную задачу с тем отличием, что они применимы к достаточно большому количеству независимых испытаний. Не нужно тушеваться слов «локальная», «интегральная», «теоремы» – материал осваивается с той же лёгкостью, с какой Лаплас потрепал кучерявую голову Наполеона. Поэтому безо всяких комплексов и предварительных замечаний сразу же рассмотрим демонстрационный пример:
Монета подбрасывается 400 раз. Найти вероятность того, что орёл выпадет 200 раз.
По характерным признакам здесь следует применить формулу Бернулли
![]() . Вспомним смысл этих букв:
. Вспомним смысл этих букв:
– вероятность того, что в независимых испытаниях случайное событие наступит ровно раз;
– биномиальный коэффициент
;
– вероятность появления события в каждом испытании;
Применительно к нашей задаче:
– общее количество испытаний;
– количество бросков, в которых должен выпасть орёл;
Таким образом, вероятность того, что в результате 400 бросков монеты орёл выпадет ровно 200 раз: …Стоп, что делать дальше? Микрокалькулятор (по крайне мере, мой) не справился с 400-й степенью и капитулировал перед факториалами . А считать через произведение что-то не захотелось =) Воспользуемся стандартной функцией Экселя , которая сумела обработать монстра: .
Заостряю ваше внимание, что получено точное значение и такое решение вроде бы идеально. На первый взгляд. Перечислим веские контраргументы:
– во-первых, программного обеспечения может не оказаться под рукой;
– и во-вторых, решение будет смотреться нестандартно (с немалой вероятностью придётся перерешивать)
;
Поэтому, уважаемые читатели, в ближайшем будущем нас ждёт:
Локальная теорема Лапласа
Если вероятность появления случайного события в каждом испытании постоянна, то вероятность того, что в испытаниях событие наступит ровно раз, приближённо равна: , где .
, где .
При этом, чем больше , тем рассчитанная вероятность будет лучше приближать точное значению , полученное (хотя бы гипотетически)
по формуле Бернулли. Рекомендуемое минимальное количество испытаний – примерно 50-100, в противном случае результат может оказаться далёким от истины. Кроме того, локальная теорема Лапласа работает тем лучше, чем вероятность ближе к 0,5, и наоборот – даёт существенную погрешность при значениях , близких к нулю либо единице. По этой причине ещё одним критерием эффективного использования формулы ![]() является выполнение неравенства ()
.
является выполнение неравенства ()
.
Так, например, если , то и применение теоремы Лапласа для 50 испытаний оправдано. Но если и , то и приближение (к точному значению ) будет плохим.
О том, почему и об особенной функции ![]() мы поговорим на уроке о нормальном распределении вероятностей
, а пока нам потребуется формально-вычислительная сторона вопроса. В частности, важным фактом является чётность
этой функции:
мы поговорим на уроке о нормальном распределении вероятностей
, а пока нам потребуется формально-вычислительная сторона вопроса. В частности, важным фактом является чётность
этой функции: ![]() .
.
Оформим официальные отношения с нашим примером:
Задача 1
Монета подбрасывается 400 раз. Найти вероятность того, что орёл выпадет ровно:
а) 200 раз;
б) 225 раз.
С чего начать решение ? Сначала распишем известные величины, чтобы они были перед глазами:
– общее количество независимых испытаний;
– вероятность выпадения орла в каждом броске;
– вероятность выпадения решки.
а) Найдём вероятность того, что в серии из 400 бросков орёл выпадет ровно раз. Ввиду большого количества испытаний используем локальную теорему Лапласа: ![]() , где
, где  .
.
На первом шаге вычислим требуемое значение аргумента:
Далее находим соответствующее значение функции: . Это можно сделать несколькими способами. В первую очередь, конечно же, напрашиваются непосредственные вычисления:
Округление проводят, как правило, до 4 знаков после запятой.
Недостаток прямого вычисления состоит в том, что экспоненту переваривает далеко не каждый микрокалькулятор, кроме того, расчёты не особо приятны и отнимают время. Зачем так мучиться? Используйте калькулятор по терверу (пункт 4) и получайте значения моментально!
Кроме того, существует таблица значений функции , которая есть практически в любой книге по теории вероятностей, в частности, в учебном пособии В.Е. Гмурмана . Закачайте, кто ещё не закачал – там вообще много полезного;-) И обязательно научитесь пользовать таблицей (прямо сейчас!) – подходящей вычислительной техники всегда может не оказаться под рукой!
На заключительном этапе применим формулу ![]() :
:
– вероятность того, что при 400 бросках монеты орёл выпадет ровно 200 раз.
Как видите, полученный результат очень близок к точному значению , вычисленному по формуле Бернулли .
б) Найдём вероятность того, что в серии из 400 испытаний орёл выпадет ровно раз. Используем локальную теорему Лапласа. Раз, два, три – и готово:
![]()
![]()
– искомая вероятность.
Ответ :
Следующий пример, как многие догадались, посвящён деторождению – и это вам для самостоятельного решения:)
Задача 2
Вероятность рождения мальчика равна 0,52. Найти вероятность того, что среди 100 новорожденных окажется ровно: а) 40 мальчиков, б) 50 мальчиков, в) 30 девочек.
Результаты округлить до 4 знаков после запятой.
…Интересно тут звучит словосочетание «независимые испытания» =) Кстати, реальная статистическая вероятность рождения мальчика во многих регионах мира колеблется в пределах от 0,51 до 0,52.
Примерный образец оформления задачи в конце урока.
Все заметили, что числа получаются достаточно малыми, и это не должно вводить в заблуждение – ведь речь идёт о вероятностях отдельно взятых, локальных значениях (отсюда и название теоремы). А таковых значений много, и, образно говоря, вероятности «должно хватить на всех». Правда, многие события будут практически невозможными .
Поясню вышесказанное на примере с монетами: в серии из четырёхсот испытаний орёл теоретически может выпасть от 0 до 400 раз, и данные события образуют полную группу
:
Однако бОльшая часть этих значений представляет собой сущий мизер, так, например, вероятность того, что орёл выпадет 250 раз – уже одна десятимиллионная: . О значениях наподобие ![]() тактично умолчим =)
тактично умолчим =)
С другой стороны, не следует недооценивать и скромные результаты: если составляет всего около , то вероятность того, орёл выпадет, скажем, от 220 до 250 раз , будет весьма заметна.
А теперь задумаемся: как вычислить данную вероятность? Не считать же по теореме сложения вероятностей несовместных событий
сумму:
Гораздо проще эти значения объединить . А объединение чего-либо, как вы знаете, называется интегрированием :
Интегральная теорема Лапласа
Если вероятность появления случайного события в каждом испытании постоянна, то вероятность ![]() того, что в испытаниях событие наступит не менее и не более раз
(от до раз включительно)
, приближённо равна:
того, что в испытаниях событие наступит не менее и не более раз
(от до раз включительно)
, приближённо равна:
При этом количество испытаний, разумеется, тоже должно быть достаточно большим и вероятность не слишком мала/велика (ориентировочно ) , иначе приближение будет неважным либо плохим.
Функция называется функцией Лапласа , и её значения опять же сведены в стандартную таблицу (найдите и научитесь с ней работать!! ). Микрокалькулятор здесь не поможет, поскольку интеграл является неберущимся. Но вот в Экселе есть соответствующий функционал – используйте пункт 5 расчётного макета .
На практике наиболее часто встречаются следующие значения:
– перепишите к себе в тетрадь.
Начиная с , можно считать, что , или, если записать строже: ![]()
Кроме того, функция Лапласа нечётна
: ![]() , и данное свойство активно эксплуатируется в задачах, которые нас уже заждались:
, и данное свойство активно эксплуатируется в задачах, которые нас уже заждались:
Задача 3
Вероятность поражения стрелком мишени равна 0,7. Найти вероятность того, что при 100 выстрелах мишень будет поражена от 65 до 80 раз.
Я подобрал наиболее реалистичный пример, а то у меня тут нашлось несколько задач, в которых стрелок делает тысячи выстрелов =)
Решение : в данной задаче речь идёт о повторных независимых испытаниях , причём их количество достаточно велико. По условию требуется найти вероятность того, что мишень будет поражена не менее 65, но и не более 80 раз, а значит, нужно использовать интегральную теорему Лапласа: , где
Для удобства перепишем исходные данные в столбик:
– всего выстрелов;
– минимальное число попаданий;
– максимальное число попаданий;
– вероятность попадания в мишень при каждом выстреле;
– вероятность промаха при каждом выстреле.
Следовательно, теорема Лапласа даст хорошее приближение.
Вычислим значения аргументов:
Обращаю ваше внимание, что произведение вовсе не обязано нацело извлекаться из-под корня (как любят «подгонять» числа авторы задач)
– без тени сомнения извлекаем корень и округляем результат; я привык оставлять 4 знака после запятой. А вот полученные значения обычно округляют до 2 знаков после запятой – эта традиция идёт из таблицы значений функции
, где аргументы представлены именно в таком виде.
Используем указанную выше таблицу либо расчётный макет по терверу
(пункт 5)
.
В качестве письменного комментария советую поставить следующую фразу: значения функции найдём по соответствующей таблице
:
– вероятность того, что при 100 выстрелах мишень будет поражена от 65 до 80 раз.
Обязательно пользуемся нечётностью функции!
На всякий случай распишу подробно:
Дело в том, что таблица значений функции
содержит только положительные «икс», а мы работаем (по крайне мере, по «легенде»)
с таблицей!
Ответ :
Результат чаще всего округляют до 4 знаков после запятой (опять же в соответствии с форматом таблицы) .
Для самостоятельного решения:
Задача 4
В здании имеется 2500 ламп, вероятность включения каждой из них в вечернее время равна 0,5. Найти вероятность того, что вечером будет включено не менее 1250 и не более 1275 ламп.
Примерный образец чистового оформления в конце урока.
Следует отметить, что рассматриваемые задачи очень часто встречаются в «обезличенном» виде, например:
Производится некоторый опыт, в котором случайное событие может появиться с вероятностью 0,5. Опыт повторяется в неизменных условиях 2500 раз. Определить вероятность того, что в 2500 опытах событие произойдет от 1250 до 1275 раз
И подобных формулировок выше крыши. По причине трафаретности задач условие нередко стремятся завуалировать – это «единственный шанс» хоть как-то разнообразить и усложнить решение:
Задача 5
В институте обучается 1000 студентов. В столовой имеется 105 посадочных мест. Каждый студент отправляется в столовую на большой перемене с вероятностью 0,1. Какова вероятность того, что в обычный учебный день:
а) столовая будет заполнена не более чем на две трети;
б) посадочных мест на всех не хватит.
Обращаю внимание на существенную оговорку «в ОБЫЧНЫЙ учебный день» – она обеспечивает относительную неизменность ситуации. После праздников в институт может прийти значительно меньше студентов, а на «День открытых дверей» нагрянуть голодная делегация =) То есть, в «необычный» день вероятности будут заметно отличаться.
Решение : используем интегральную теорему Лапласа , где
В данной задаче:
– всего студентов в институте;
– вероятность того, что студент отправится в столовую на большой перемене;
– вероятность противоположного события.
а) Вычислим, сколько посадочных мест составляют две трети от общего количества: мест
Найдём вероятность того, что в обычный учебный день столовая будет заполнена не более чем на две трети. Что это значит? Это значит, что на большой перемене придут от 0 до 70 человек. То, что никто не придёт или придут всего несколько студентов – есть события практически невозможные
, однако в целях применения интегральной теоремы Лапласа эти вероятности все равно следует учесть. Таким образом: ![]()
Вычислим соответствующие аргументы:
В результате:
– вероятность того, что в обычный учебный день столовая будет заполнена не более чем на две трети.
Напоминание : при функцию Лапласа считаем равной .
Толкучка, однако =)
б) Событие «Посадочных мест на всех не хватит»
состоит в том, что в столовую на большой перемене придут обедать от 106 до 1000 человек (главное, хорошо уплотнить =)).
Понятно, что высокая посещаемость невероятна, но тем не менее: ![]() .
.
Рассчитываем аргументы:
Таким образом, вероятность того, что посадочных мест на всех не хватит:
Ответ :
А теперь остановимся на одном важном нюансе
метода: когда мы проводим вычисления на отдельно взятом отрезке
, то всё «безоблачно» – решайте по рассмотренному шаблону. Однако в случае рассмотрения полной группы событий
следует проявить определённую аккуратность
. Поясню этот момент на примере только что разобранной задачи. В пункте «бэ» мы нашли вероятность – того, что посадочных мест на всех не хватит. Далее, по той же самой схеме рассчитаем:
– вероятность того, что мест хватит.
Поскольку эти события противоположны
, то сумма вероятностей должна равняться единице:
В чём дело? – вроде бы тут всё логично. Дело в том, что функция Лапласа является непрерывной
, а мы не учли интервал
от 105 до 106. Вот здесь то и пропал кусочек 0,0338. Поэтому по той же самой стандартной формуле
следует вычислить:
Ну, или ещё проще:
Возникает вопрос
: а что, если мы СНАЧАЛА нашли ? Тогда будет другая версия решения:
Но как так может быть?! – в двух способах получаются разные ответы! Всё просто: интегральная теорема Лапласа – это метод приближённого вычисления, и поэтому приемлемы оба пути.
Для более точных расчётов следует воспользоваться формулой Бернулли
и, например, экселевской функцией БИНОМРАСП
. В результате её применения
получаем:
И я выражаю благодарность одному из посетителей сайта, который обратил внимание на эту тонкость – она выпала из моего поля зрения, так как исследование полной группы событий редко встречается на практике. Желающие могут ознакомиться с
Интегральная теорема Муавра-Лапласа . Если вероятность р наступления события А в каждом испытании постоянна и отлична от 0 и 1, то вероятность того, что число m наступления события А в n независимых испытаниях заключено в пределах от а до b (включительно), при достаточно большом числе n приближенно равна
Где
 - функция (или интеграл вероятностей)
Лапласа;
- функция (или интеграл вероятностей)
Лапласа;
 ,
,
 .
.
Формула называется
интегральной формулой МуавраЛапласа.
Чем больше n, тем точнее эта формула. При
выполнении условия npq ≥ 20 интегральная
формула
 ,
так же как и локальная, дает, как правило,
удовлетворительную для практики
погрешность вычисления вероятностей.
,
так же как и локальная, дает, как правило,
удовлетворительную для практики
погрешность вычисления вероятностей.
Функция Ф(х) табулирована (см. табл.). Для применения этой таблицы нужно знать свойства функции :
Функция Ф(х) нечетная, Т.е. Ф(-х) = -Ф(х).
Функция Ф(х) монотонно возрастающая, причем при х → +∞ Ф(х) → 1 (практически можно считать, что уже при х > 4 Ф(х) ≈ 1).
Пример . В некоторой местности из каждых 100 семей 80 имеют холодильники. Вычислить вероятность того, что от 300 до 360 (включительно) семей из 400 имеют холодильники.
Решение . Применяем интегральную теорему МуавраЛапласа (npq = 64 ≥ 20). Вначале определим:
 ,
,
 .
.
Теперь по формуле
 ,
учитывая свойства Ф(х), получим
,
учитывая свойства Ф(х), получим
(по табл. Ф(2,50) = 0,9876, Ф(5,0) ≈ 1)
Следствия из интегральной теоремы Муавра-Лапласа (с выводом). Примеры.
Рассмотрим следствие интегральной теоремы МуавраЛапласа.
Следствие . Если вероятность р наступления события А в каждом испытании постоянна и отлична от 0 и 1, то при достаточно большом числе n независимых испытаний вероятность того, что:
а) число m
наступлений события А отличается от
произведения nр
не более, чем на величину ε >  ;
;
б) частость
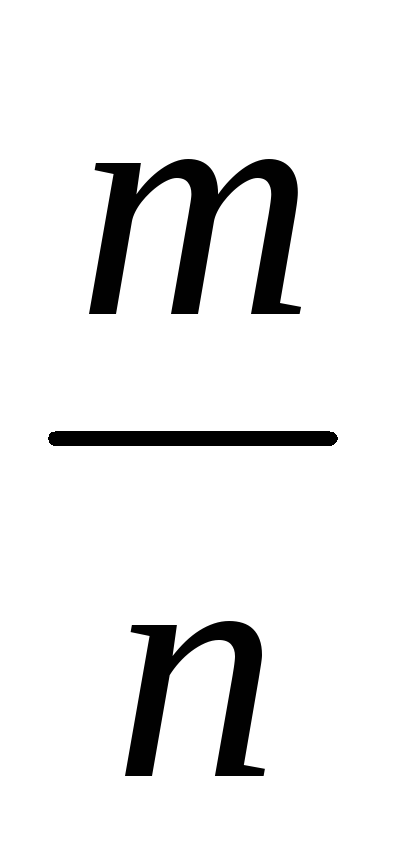 события
А заключена в пределах от α до β
(включительно), т.е.
события
А заключена в пределах от α до β
(включительно), т.е.
 ,
Где
,
Где
 ,
, .
.
в) частость
 события А отличается от его вероятности
р не более, чем на величину Δ > 0 (по
абсолютной величине), т.е.
события А отличается от его вероятности
р не более, чем на величину Δ > 0 (по
абсолютной величине), т.е.
 .
.
□ 1) Неравенство
 равносильно двойному неравенству пр
- Е ~ т ~ пр + Е. Поэтому по интегральной
формуле
равносильно двойному неравенству пр
- Е ~ т ~ пр + Е. Поэтому по интегральной
формуле :
:
 .
.
2) Неравенство
 равносильно
неравенствуa
≤ m
≤ b
при a
= nα
и b
= nβ.
Заменяя в формулах
равносильно
неравенствуa
≤ m
≤ b
при a
= nα
и b
= nβ.
Заменяя в формулах
 и
и ,
, величины а иb
полученными выражениями, получим
доказываемые формулы
величины а иb
полученными выражениями, получим
доказываемые формулы
 и
и ,
, .
.
3) Неравенство
 равносильно
неравенству
равносильно
неравенству .
Заменяя в формуле
.
Заменяя в формуле
 ,
получим доказываемую формулу
,
получим доказываемую формулу .
.
Пример . По статистическим данным в среднем 87% новорожденных доживают до 50 лет. Найти вероятность того, что из 1000 новорожденных доля (частость) доживших до 50 лет будет: а) заключена в пределах от 0,9 до 0,95; б) будет отличаться от вероятности этого события не более, чем на 0,04 (по абсолютной величине)?
Решение . а) Вероятность р того, что новорожденный доживет до 50 лет, равна 0,87. Т.к. n = 1000 велико (условие npq = 1000·0,87·0,13 = 113,1 ≥ 20 выполнено), то используем следствие интегральной теоремы Муавра-Лапласа. Вначале определим:
 ,
,
 .
Теперь по формуле
.
Теперь по формуле :
:
Б) По формуле
 :
:
Так как неравенство
 равносильно неравенству
равносильно неравенству ,
полученный результат означает, что
практически достоверно, что от 0,83 до
0,91 числа новорожденных из 1000 доживут
до 50 лет.
,
полученный результат означает, что
практически достоверно, что от 0,83 до
0,91 числа новорожденных из 1000 доживут
до 50 лет.
Понятие «случайная величина» и ее описание. Дискретная случайная величина и ее закон (ряд) распределения. Независимые случайные величины. Примеры.
Под случайной величиной понимается переменная, которая в рез-те испытания в зав-ти от случая принимает одно из возможного множества своих значений (какое именно - заранее не известно).
Примеры случайных величин : 1) число родившихся детей в течение суток в г. Москве; 2) количество бракованных изделий в данной партии; 3) число произведенных выстрелов до первого попадания; 4) дальность полета артиллерийского снаряда; 5) расход электроэнергии на пр-тии за месяц.
Случайная величина называется дискретной (прерывной) , если множество ее значений конечное, или бесконечное, но счетное.
Под непрерывной случайной величиной будем понимать величину, бесконечное несчетное множество значений которой - некоторый интервал (конечный или бесконечный) числовой оси.
Так, в приведенных выше примерах 1-3 имеем дискретные случайные величины (в примерах 1 и 2 - с конечным множеством значений; в примере 3 - с бесконечным, но счетным множеством значений); а в примерах 4 и 5 - непрерывные случайные величины.
Для дискретной
случайной величины
множество
 возможных значений случайной величины,
т.е. функции
возможных значений случайной величины,
т.е. функции ,
конечно или счетно, длянепрерывной
- бесконечно и несчетно.
,
конечно или счетно, длянепрерывной
- бесконечно и несчетно.
Случайные величины обозначаются прописными буквами латинского алфавита Х,У,Z,..., а их значения - соответствующими строчными буквами х,у,z,....
Про случайную величину говорят, что она «распределена» по данному закону распределения или «подчинена» этому закону распределения.
Для дискретной случайной величины закон распределения м.б. задан в виде таблицы, аналитически (в виде формулы) и графически.
Простейшей формой задания закона распределения дискретной случайной величины Х является таблица (матрица), в которой перечислены в порядке возрастания все возможные значения случайной величины и соответствующие их вероятности, т.е.
 .
.Такая таблица называется рядом распределения дискретной случайной величины .
События Х=х 1 ,
Х=x 2 ,…,Х=x n ,
состоящие в том, что в результате
испытания случайная величина Х примет
соответственно значения х 1 ,
x 2 ,
..., x n
являются несовместными и единственно
возможными (ибо в таблице перечислены
все возможные значения случайной
величины), Т.е. образуют полную группу.
Следовательно, сумма их вероятностей
равна 1. Т.о., для любой дискретной
случайной величины
 .
.
Ряд распределения м.б. изображен графически, если по оси абсцисс откладывать значения случайной величины, а по оси ординат - соответствующие их вероятности. Соединение полученных точек образует ломаную, называемую многоугольником или полигоном распределения вероятностей .
Две случайные величины называются независимыми , если закон распределения одной из них не меняется от того, какие возможные значения приняла другая величина. Так, если дискретная случайная величина Х может принимать значения x i (i = 1, 2, ..., n), а случайная величина У - значения y j (j = 1, 2, ..., m), то независимость дискретных случайных величин Х и У означает независимость событий Х = x i и У = y при любых i = 1, 2, ... , n и j = 1, 2, ..., m. В противном случае случайные величины называются зависимыми .
Например , если имеются билеты двух различных денежных лотерей, то случайные величины Х и Y, выражающие соответственно выигрыш по каждому билету (в денежных единицах), будут независимыми , т.к. при любом выигрыше по билету одной лотереи (например, при Х = x i) закон распределения выигрыша по другому билету (У) не изменится.
Если же случайные величины Х и У выражают выигрыш по билетам одной денежной лотереи, то в этом случае Х и У являются зависимыми, ибо любой выигрыш по одному билету (Х = x i) приводит к изменению вероятностей выигрыша по другому билету (У), т.е. к изменению закона распределения У.
Математические операции над дискретными случайными ве личинами и примеры построения законов распределения для КХ, Х" 1 , X + К, XV по заданным распределениям независимых случай ных величин X и У.
Определим математические операции над дискретными случайными величинами.
Пусть даны две случайные величины:
Произведением kX случайной величины Х на постоянную величину k называется случайная величина, которая принимает значения kx i с теми же вероятностями р i (i = 1,2,...,n).
m
-й
степенью случайной величины Х, т.е.
 ,
называется случайная величина, которая
принимает значения
,
называется случайная величина, которая
принимает значения
 с теми же вероятностями р i
(i = 1,2,...,n).
с теми же вероятностями р i
(i = 1,2,...,n).
Суммой (разностью или произведением) случайных величин Х и У называется случайная величина, которая принимает все возможные значения вида хi+уj (хj-уj или хj·уj), где i = l,2,...,n; j =1,2,...,m, с вероятностями pij того, что случайная величина Х примет значение xi, а у - значение yj:
Если случайные величины Х и У независимы, т.е. независимы любые события Х=хi, Y=yj то по теореме умножения вероятностей для независимых событий
3амечание
.
Приведенные выше определения операций
над дискретными случайными величинами
нуждаются в уточнении: так как в ряде
случаев одни и те же значения
 ,
, ,
, могут получаться разными способами при
различныхxi,
yj
с вероятностями pi,
pij,
то вероятности таких повторяющихся
значений находятся сложением полученных
вероятностей pi
или pij.
могут получаться разными способами при
различныхxi,
yj
с вероятностями pi,
pij,
то вероятности таких повторяющихся
значений находятся сложением полученных
вероятностей pi
или pij.
|
Вид операции |
Выражение знач. Сл\в |
Выр знач вер-ти |
|
|
|
|
|
|
||
|
|
|
|
|
|
|


 не изм-ся
не изм-ся не изм-ся
не изм-ся





